Testing collaborating microservices in Production
Adding observability and cross-application monitoring to microservices

You want to be confident that your users can keep using your service to achieve their goals.
Monitoring the health of individual microservices is not enough.
You need assurance that key suites of microservices are working well together to meet those goals. And when they aren't, you need the information necessary to swiftly fix problems.
I've helped build a number of micro-service systems. I've learned that it's hard to comprehensively test them before shipping without losing some of the key value of building independent services.
I've had to look for new ways to identify and diagnose problems so that teams can keep moving fast and shipping with confidence.
Trying (and failing) with cross-service monitoring
in the early days of a project, I hoped that I could solve it using the same system that was in use to monitor the services. Could I set useful cross-service-boundary assertions in our monitoring tool?
Using the instrumentation I already had in my services, I experimented with new monitors. I knew a user submit action in one service should always result in a PDF render in another. I laid out an expectation that these 2 key metrics should always match. If not, the team should get an alert.
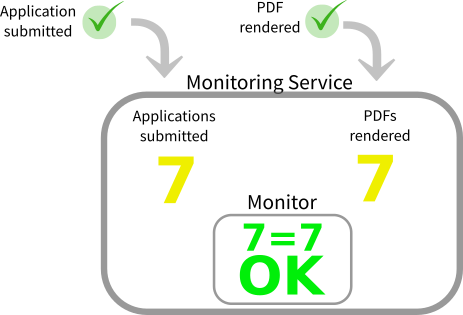
Initially, these monitors gave the team a lot of useful feedback and confidence. So we rolled out more similar checks. The team moved from knowing what each service was doing, to having more confidence that our system was working together.
The Bad news
Though it was really helpful and caught some bugs, It didn't quite work. Not all the time.
It produced false alarms. Operations still in progress looked like failures to our monitoring system. Requests get queued around systems and processed at different paces and so counts would not always match.
...and more bad news
Not only that but when there was an alert the team did not have the data needed to act. The monitoring data emitted didn't provide the depth necessary to solve problems or know whether there had been a false alarm.
The team need to be able to observe what the systems were doing.
The solution to this thankfully also provided a solution to our false alarms.
Building an audit record from distributed behaviours
To get the Observability we needed, a detailed audit log was added, held in our main data store. This recorded the critical events taken by users and added actions that then happened asynchronously in other services.
This gave the team a more global view and gave the team the ability to reason about the system. This proved super useful for supporting users and solving problems.
Application Monitoring from the audit trail
The scripts the team built to examine the audit trail quickly became more accurate than the monitor expectations that sent us alerts. This changed gear. These scripts were turned into code to drive new alerts, running in a microservice — with the aim of more accuracy and fewer false alarms.
This new custom monitoring would check our expectations only after it was likely that all downstream operations would be complete. Additionally, it could dig into detail that the original monitoring system did not have rather than checking summed up totals.
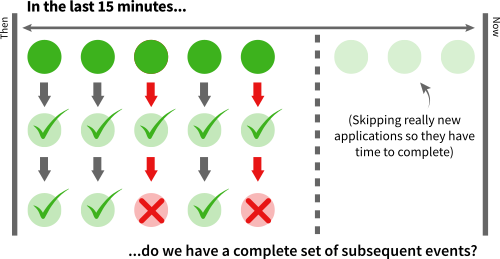
This reduced the false alarms to zero, giving us a reliable system that told us when an application submission was not getting processed correctly by one of our microservices.
Even better, it could tell us the details of the fault whenever it caught a problem.
Note: building custom monitoring comes at a higher cost. The code that operated over the audit log and raised alerts needed to be maintained. It's well worth checking that you'll see a return on the investment.
Gain confidence via data to ship and move fast
I learned that to be able to accurately spot problems and react quickly to unexpected situations I needed to instrument our software at a sufficient level of detail, allowing us to think and code about individual user events.
I also learned that we didn't need to do all that at the start; I could build a noisier, simpler system and finesse it as I shipped and learned more. By focusing on the problems I had, I progressively reduced the support workload, chunk by chunk.
Credits
Cover Photo by Bill Oxford on Unsplash